pathlib read_text()の日本語ファイルのエンコードエラーを解決
長らくos.pathを使っていたのですが最近pathlibに移行しました。
まだ使い慣れていませんが、pathlibはかなり楽でびっくりしました!
そんなわけで、今回はpathlibのread_text()でunicodeを含むファイルの読み込み時に遭遇したエラーの解決手順を記載します。
私はjsonファイルの読み込みで遭遇しましたが、txtファイルやcsvファイルの読み込みでも同様の問題に遭遇すると思います。
余談ですが、pythonで多言語対応したスクリプト向けにConfigファイルの設定値に従い文字列を表示するリポジトリを公開しました。
github.com
環境
OS:Windows10
Python:3.6.8
エラー内容
from pathlib import Path
file_path = Path("tset.json")
data = file_path.read_text()
File "C:\Users\user\AppData\Local\Programs\Python\Python36\lib\pathlib.py", line 1197, in read_text
return f.read()
UnicodeDecodeError: 'cp932' codec can't decode byte 0x86 in position 20: illegal multibyte sequence
解決策
read_textの引数であるencodingに"utf-8"を設定します。
from pathlib import Path
file_path = Path("tset.json")
data = file_path.read_text(encoding="utf-8"))これでエラーが発生せず、日本語が読めるようになりました。
仕事の効率化の基本「辞書登録」
こんばんは、yamamon嫁ことどらねこです。
今回ご紹介するのは「辞書登録」です。
今更感もありますが、社会人になりたての頃にとてもお世話になったので書き留めます。
メール等で文章を作成するとき、お決まりの言葉ってありますよね。
例えば……
・お疲れ様です。<氏名>です。
・いつもお世話になっております。
・よろしくお願いいたします。
・今後ともよろしくお願いいたします。
などなど、お作法は立場によりいろいろあれど、
定型的な表現ってあると思います。
今例に挙げたものだけでも、毎回手入力だと時間がかかっちゃいますよね。
こんな時に活用するのが辞書登録。
辞書登録は本来、
IMEの辞書ファイルに登録のない単語を利用者が必要に応じて登録するものです。
この機能、自由度が高いので、
登録方法を工夫すればお仕事の効率化にも役立つんです!
では、登録方法をご紹介します。
登録方法
登録方法は主に以下の2つです。
①1単語ずつの登録
②複数の単語を一括で登録
①1単語ずつの登録
1.マルチタスクバーの入力文字の表示(下記画像では「A」)を右クリックし、IMEオプションを開く
2.「IMEオプション>単語の追加」をクリック、「単語登録」ウインドウが開く
3. 「単語」に変換後の文字列を入力
4.「よみ」に変換前 の文字列を入力
5.※任意
「ユーザ コメント(C)」にコメントを記載
6.「品詞(P)」を選択
7.「登録」ボタンをクリック
実際にテキスト等で登録した内容を試し打ちするとより確実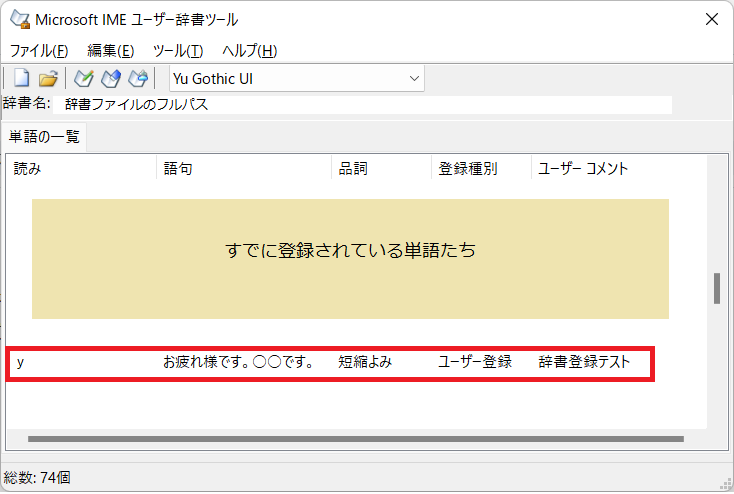
②複数の単語を一括で登録
※辞書登録したい内容が複数ある場合はこちらの方法が圧倒的におすすめ
1.辞書登録したい内容をテキストファイルに記入し、保存する
<記入ルール>
・tab区切りで「よみ」「単語」「品詞」の順に記載
・次の単語を記載する際は改行
・レイアウトを整えるの必要はない
・保存は「Shift-JIS」または「UTF-16LE」
※「UTF-8」はエラーになる。どんなエラーになるかは本記事の最後に記載。
下図参考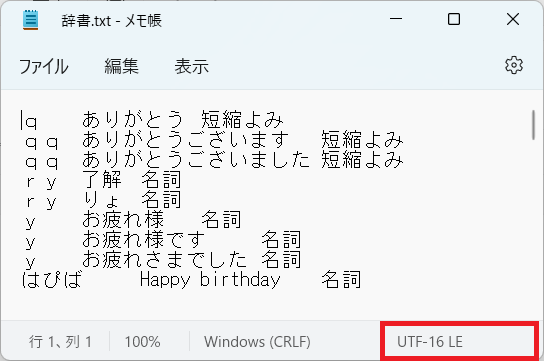
2.マルチタスクバーの入力文字の表示(下記画像では「A」)を右クリックし、IMEオプションを開く
3.「IMEオプション>単語の追加」をクリック、「単語登録」ウインドウが開く
4.「単語登録」ウインドウの「ユーザ辞書ツール」をクリックし、「Microsoft IMEユーザ辞書ツール」ウインドウを開く
5.「ツール>テキストファイルからの登録」をクリック、「テキストファイルからの登録」ウィンドウを開く
6.1にて作成したテキストファイルを選択し、「開く(O)」をクリック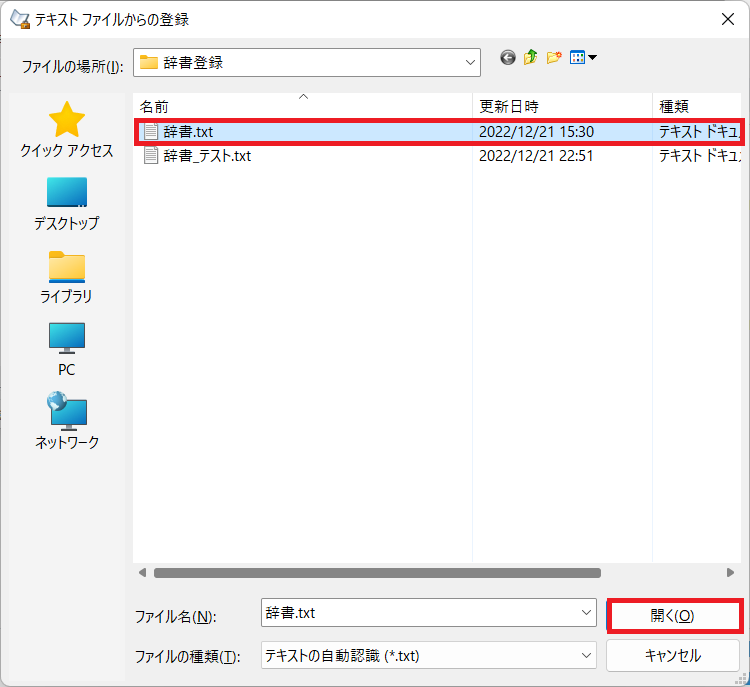
実際にテキスト等で登録した内容を試し打ちするとより確実
~余談~
②複数の単語を一括で登録でテキストファイルを「UTF-8」で保存したらどうなるのか!
使ったのは下図のファイル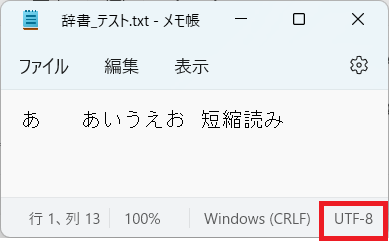
エラーログも出力できるので、せっかくなので中身を見てみましょう。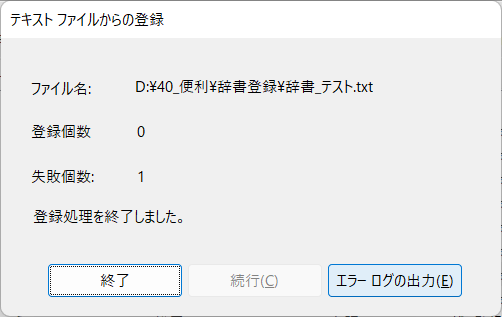
そして、エラーログも「UTF-16LE」で出力されています。
どらねこの辞書の中身
趣味PCで書いているため、辞書ファイルの中身は恥ずかしくてお見せできませんが、
実際にどのような内容を登録しているのかもメモ書き程度に残します。
仕事ver
メールの枕詞系は基本的に登録しています。
普段あまり使わないキーを割り当てて、短縮読み登録することが多いです。
・お疲れ様です。○○です。
・いつもお世話になっております。
同じ「よみ」に二つ単語を割り当てることもあります。
・qq→ありがとうございます/ありがとうございました
まだまだ下っ端なので、確認依頼を出す機会がとても多いです。
・ご確認よろしくお願い致します。
人の名前や会社名は間違えると大変失礼なので、よく使う人&一発変換で出ない人は登録してます。
あと、謝る機会は少ないほうがいいです。
でも、いちいちちゃんと打つとダメージ食らうので短縮読みで登録しました。
・申し訳ありません。
・申し訳ございません。
推しごとver
アニメや映画の登場人物って一発変換で出てきにくいので登録してます。
カップリングは一発変換がまずできないので、登録しておくと変換ミスがなくてストレスが減ります。
長々と失礼しました。
ではまたいつか。
ごあいさつ
はじめましてyamamon嫁ことどらねこです。
「自分の備忘録を兼ねて、仕事で調べた知識を書き留めるブログを作りたい」
と主人に相談したところ、一緒にこちらのブログを更新することとなりました。
このブログの趣旨である
「私生活で得た情報を共有すること」を逸脱しない内容になるよう頑張ります^^
主人の記事よりもかなりゆるい内容になるかとは思いますが、よろしくお願いいたします。
ではでは、軽く自己紹介を……
どらねこ
仕事:IT関連
好きなもの:映画、演劇、アニメ、甘いもの、人の金で食べる焼肉、酒
よろしくお願いいたします<(_ _)>
Raspberry Pi4 最小サイズでのimageファイル作成手順
Raspberry Piのバックアップなどの目的でimageファイルを作成することがありますが、その容量を小さくする方法を紹介します。
作成したimageファイルが大きいために、バックアップ/レストア作業に時間がかかったり、レストアに失敗することもあります。
そのような問題点を解決するためimageファイルの縮小は欠かせません。
環境は以下となります。
環境:Raspberry Pi 4、UbuntuMATE
では早速手順を紹介します。
用意する物
・ubuntuがインストールされたPC
・PC用のSDカードリーダ
imageファイル縮小のメリット
imageファイルを小さくするメリットですが、以下の3点が挙げられます。
・SDカードの個体差の影響を受けにくい
・imageファイルサイズ以上であればより使用しているSDカードより容量の小さなSDへも使用可能
・バックアップ、レストア時間が短縮できる
領域最小化手順
1.Raspberry Piをシャットダウンし、microSDカードを抜いてPCに接続
2.superキーを押下しアクティビティを開き、Disksと検索してDisksを起動
3.左のPanelから対象SDカードを選択
4.Partition2 (Ext4)を選択
5.歯車マークを押下
6.Resizeを選択
7.スライダーを最小より1GB大きい状態に移動
8.実行
ダイアログが閉じ、Job欄がRepairing FilesystemsかResizing Filesystemになったことを確認
実行終了まで待つ
Valumes欄(ディスク容量)にFree Spaceができれば完了
9.terminalを開く
10. 該当するSDカードを探す
df -h

↑の画像のような出力が表示されるので/media/user名/system-bootとなっているFilesystemを探す
(例)/dev/sda1
11. partitionサイズの確認
前手順で調べたFilesystemから末尾の1を抜いた名前を【filesystem名】とし、↓のコマンドを実行する
sudo fdisk -l 【filesystem名】
私の場合はfilesystem名が/dev/sda1だったので、sudo fdisk -l /dev/sda
実行すると↓のようなログが出力される。

12.最終行に表示される、4列目のEnd(最後、最後までと表示される場合あり)の値を控える
デバイスの末尾に1がついている方(/dev/sda1)はシステム領域で250MBくらいあります。
デバイスの末尾に2がついている方(/dev/sda2)がRaspberry Piとして使用している領域となります。
単位が512Bのため大きな値が記載されています。
13.Ctrl + C で終了。
backup / restore 手順
1.terminalを開く
2. SDカードのドライブ名を確認する
df -h
領域最小化手順10.で調べた内容と同じはずですが念のため確認してください。
3.ドライブをアンマウントする
前手順で調べたFilesystemから末尾の1を抜いた名前を【filesystem名】とし、↓のコマンドを実行する。
umount 【filesystem名】 (例)umount /dev/sdb
4.バックアップコマンドを実行
領域最小化手順 13で控えた値を2048で割った値を切り上げます。
→控えた値が512B単位でバックアップは1MB単位で実行するため、
1MB単位でのサイズを計算しています。
>>> 33730559 / 2048 16469.99951171875 →16470
sudo dd bs=1M if=【ドライブ名】 of=【保存先】 count=カウント (例) sudo dd bs=1M if=/dev/rdisk3 of=./RPi4.img count=31729
5.復元する場合は前手順のドライブ名と保存先を入れ替えます。
sudo dd bs=1M if=【保存先】 of=【ドライブ名】 (例) sudo dd bs=1M if=./RPi4.img of=/dev/rdisk3
CPU環境でdarknetの高速化
CPU環境でdarknetの推論速度を高速化する手順を紹介します。
環境は以下となります。
環境:Raspberry Pi 4、Ubuntu MATE
使用するのは下記URLのdarknetとNNPACKを組み合わせたコードです。
GitHub - digitalbrain79/darknet-nnpack: Darknet with NNPACK
- 推論速度
- 気をつける点
- PeachPy と confu のインストール
- Ninja のインストール
- clang のインストール
- NNPACK 関連のライブラリのバージョン変更
- NNPACK-darknet インストール(2)
- darknet-nnpack のビルド
推論速度
640 x 424の画像に対してpre-trainedモデルを使用し推論速度を比較しました。
YOLOv3-tiny:0.67秒
YOLOv3:5.50秒
PeachPy と confu のインストール
sudo pip install --upgrade git+https://github.com/Maratyszcza/PeachPy sudo pip install --upgrade git+https://github.com/Maratyszcza/confu
Ninja のインストール
cd git clone https://github.com/ninja-build/ninja.git cd ninja git checkout release ./configure.py --bootstrap export NINJA_PATH=$PWD
clang のインストール
sudo apt install clang **NNPACK-darknet インストール(1) >|bash| cd git clone https://github.com/digitalbrain79/NNPACK-darknet.git cd NNPACK-darknet confu setup
NNPACK 関連のライブラリのバージョン変更
NNPACK 関連のライブラリの最新バージョンにNNPACK-darknetが対応していないため、deps フォルダ配下の NNPACK に関連するライブラリのバージョンを2018年11月8日以前に変更します。
cd deps/fp16 git checkout 34d4bf01bbf7376f2baa71b8fa148b18524d45cf cd ../fxdiv git checkout 811b482bcd9e8d98ad80c6c78d5302bb830184b0 cd ../psimd git checkout 3d8bfe7318423462a6d9e0c6537e75efd4822c49 cd ../pthreadpool git checkout 13da0b4c21d17f94150713366420baaf1b5a46f4
NNPACK-darknet インストール(2)
cd ../../ python3 ./configure.py --backend auto $NINJA_PATH/ninja sudo cp -a lib/* /usr/lib/ sudo cp include/nnpack.h /usr/include/ sudo cp deps/pthreadpool/include/pthreadpool.h /usr/include/
darknet-nnpack のビルド
cd git clone https://github.com/digitalbrain79/darknet-nnpack.git cd darknet-nnpack make
Windows10とUbuntuのデュアルブートで1週間ほど嵌った
最近買ったwindowsPCをubuntuとのデュアルブートしようとして、過去と同じところで詰まったので備忘録として残します。
デュアルブート環境の構築手順は↓のサイトを参考にしました。
Windows 10とUbuntu 18.04 デュアルブートする方法 | パソコン工房 NEXMAG
QFileDialogでfileとdirectory両方を選択可能とする。
QFileDialogはファイルなどを開いたり保存するウインドウを作成するクラスです。
中でもstatic関数を使用することでファイルやフォルダのopen、save用のウインドウを簡単に作成できます。
今回、一つのウィンドウからファイルとフォルダ両方を開きたかったのですが、ちょっと実装に手間取ったので記録します。
※windows、mac、ubuntuで動作確認したところ、mac以外では正常に動作しないようです。
環境:python3.6.8, PyQt5
リファレンス:QFileDialog Class | Qt Widgets 5.15.0
PyQt5での実装
dialog = QFileDialog()
ret_data = []
if dialog.exec():
ret_data = dialog.selectedFiles()
print(ret_data)
簡単に解説すると、static関数で実装されているgetExistingDirectory()やgetOpenFileName()を使うとdirectoryかfileのいずれかのパスしか取得できません。
そのため、QFileDialogの表示モードなどを自前で設定し、表示する必要があります。
ただし、FileModeはデフォルトでAnyFile、つまり存在するかどうかに関係なくファイル名を選択できる状態ですし、Optionにも表示をディレクトリのみに制限するオプションも有効になっていませんので特に設定する必要もありません。
したがって、3行目のdialog.exec()を実行することでファイルダイアログを表示できます。
exec()は親クラスのQDialog::exec()を呼び出しています。
この関数はダイアログを表示し、表示がダイアログの処理が終了するまで他の処理をブロックします。
また、正常終了時には1、キャンセルなどの異常終了時には0を返却します。
そのため、4行目では正常終了した場合に画面に表示したダイアログで選択されたファイルを取得するようにしています。